

Understanding GPU Usage & Influencing Job Scheduling with Altair PBS Professional
This post was co-authored by Scott Suchyta, Hiroji Kubo, and Kumar Vaibhav Pradipkumar Saxena at Altair.
Understanding the operational status of the GPU and incorporating the GPU’s health in the decisions of the job scheduler is useful for ensuring users optimal job placement. It also helps administrators understand the usage of GPU resources for planning resource allocation.
Background
The oldest academic supercomputing center in Japan, the University of Tokyo, is making plans for a future exascale system that can manage HPC and deep learning applications. As you would expect, current supercomputing systems are executing more traditional engineering, earth sciences, energy sciences, materials, and physics applications. The site has seen a growing demand for executing biology, biomechanics, biochemistry, and deep learning applications. The new applications require computational accelerators, and the site has invested in NVIDIA® Tesla® P100 GPUs to increase utilization and productivity for engineers and scientists. This is the first time that the Information Technology Center (ITC) at the University of Tokyo has adopted a computational accelerator in a supercomputer.
Referring to Figure 1, Reedbush is a supercomputer with three subsystems: Reedbush-U, which comprises only CPU nodes; Reedbush-H, which comprises nodes with two GPUs mounted as computational accelerators; and Reedbush-L, which comprises nodes with four GPUs mounted. These subsystems can be operated as independent systems.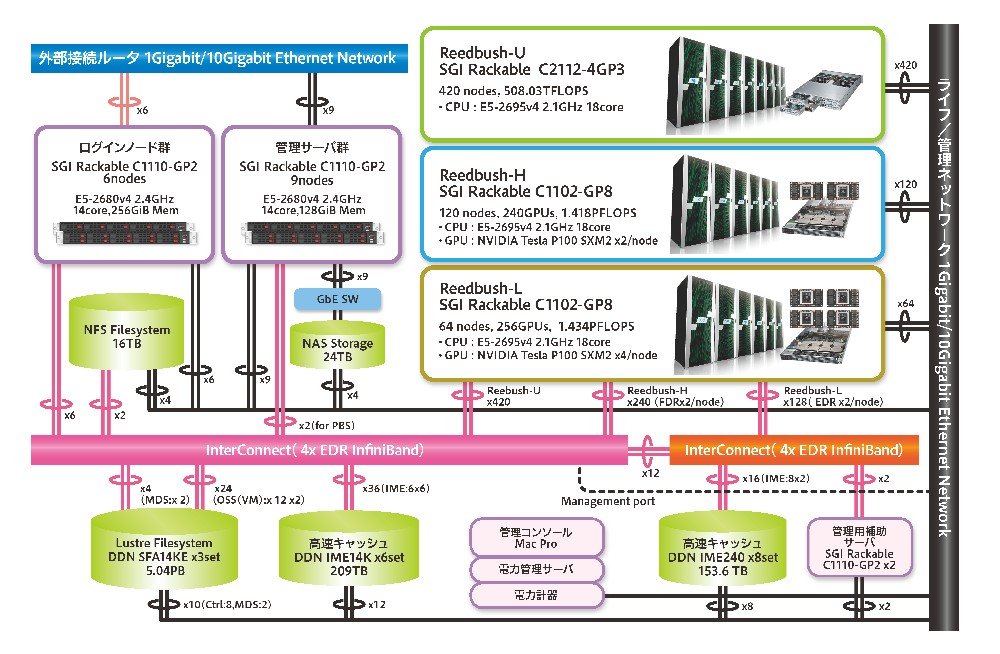
Figure 1 https://www.cc.u-tokyo.ac.jp/en/supercomputer/reedbush/system.php
With all the computational power in the three systems, the University of Tokyo’s ITC required a solution that would provide its users with a robust, resilient, and power-efficient environment to ensure that their designs and scientific discoveries run to completion. Hewlett-Packard Enterprise (HPE) and Altair collaborated on the project, which entailed integrating GPU monitoring using the NVIDIA Data Center GPU Manager (DCGM) with Altair PBS Professional™ on the Reedbush supercomputer.
The How
HPE collaborated with Altair to develop GPU monitoring and workload power management capabilities within PBS Professional. The solution includes the usage of NVIDIA DCGM, which is a low-overhead tool suite that performs a variety of functions on each host system, including active health monitoring, diagnostics, system validation, policies, power and clock management, group configuration, and accounting.
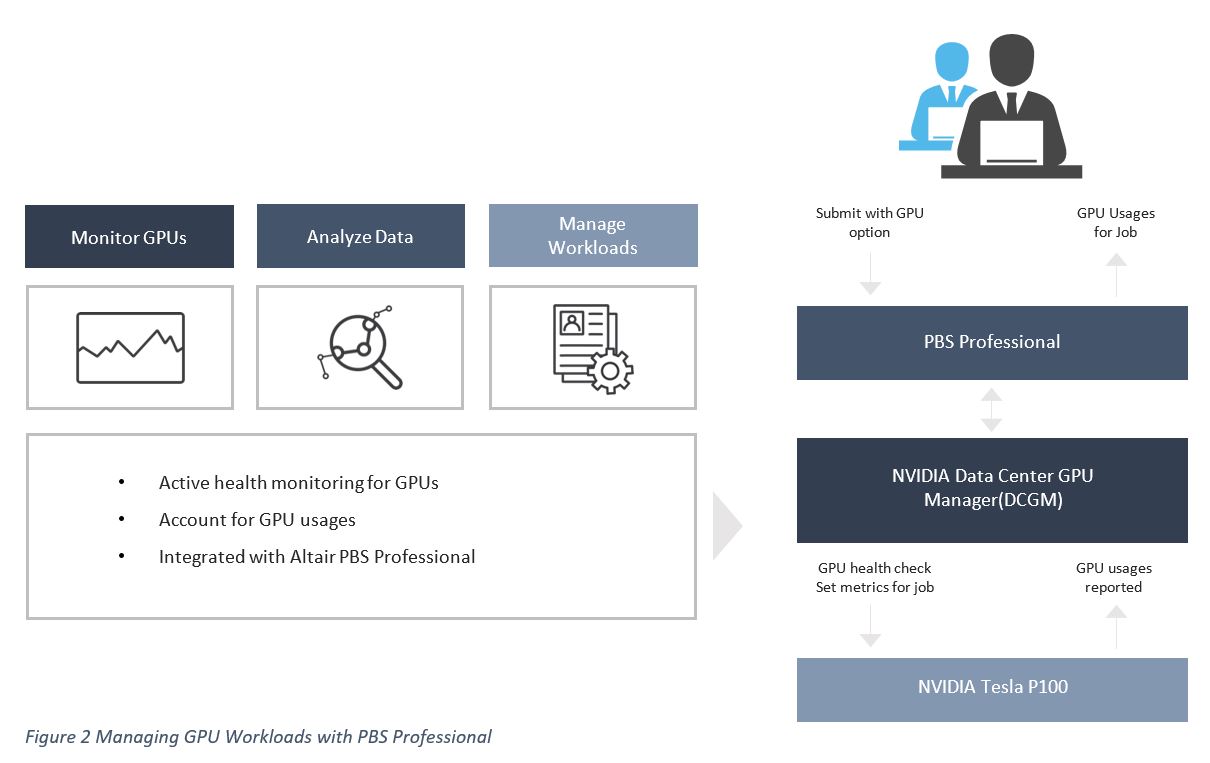
PBS Professional and NVIDIA DCGM Integration
The PBS Professional and NVIDIA DCGM integration includes the following benefits and functionalities:
- Increase system resiliency
- Automatically monitor node health
- Automatically run diagnostics on GPUs
- Reduce the risk of jobs failing due to GPU errors
- Prevent jobs from running on nodes with GPU environment errors
- Optimize job scheduling through GPU load and health monitoring
- Provide node health information to help administrators and users understand how jobs are being affected
- Record GPU usage for future planning
The integration relies on a few of the PBS Professional plugin events (a.k.a. hooks), as seen in Figure 3 and Figure 4 below. I’m not going to talk about all of these plugins/hook events in this article, but I recommend that you review the PBS Professional Administrator Guide
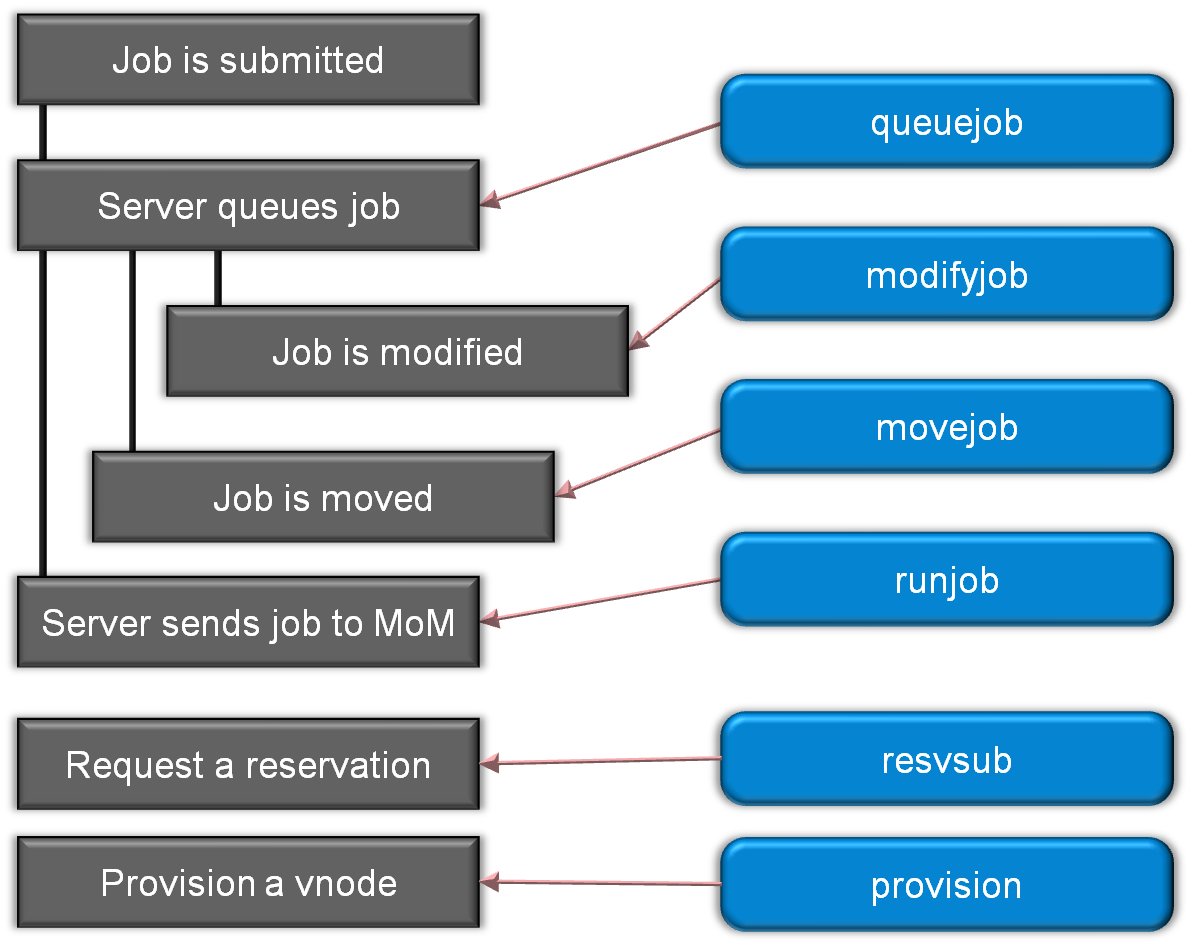
Figure 3 Admission Control and Management Plugins
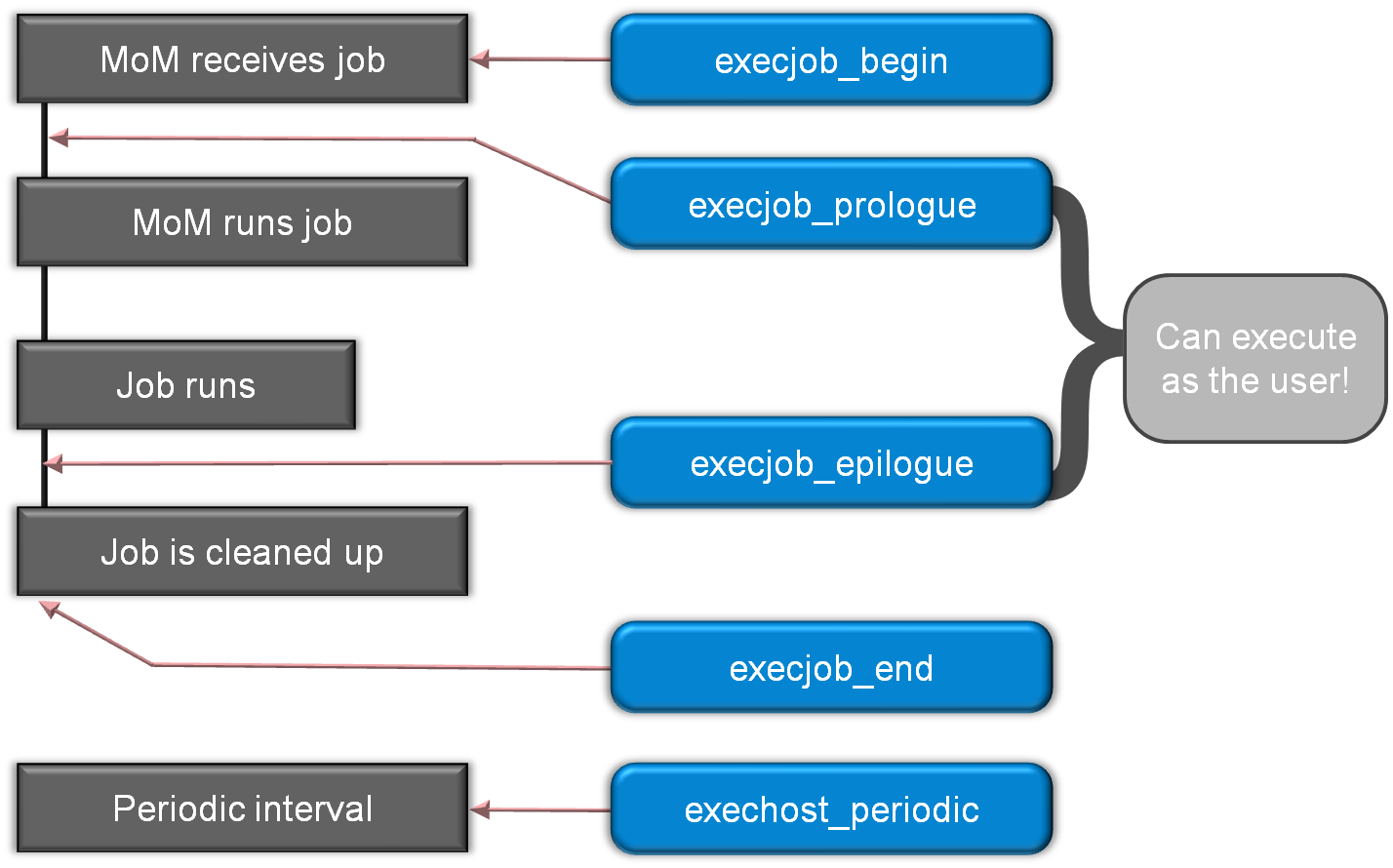
Figure 4 Job Execution Plugins
A little background on hooks. Hooks are custom executables that can be run at specific points in the life cycle of a job. Each type of event has a corresponding type of hook and can accept, reject, or modify the behavior of the user's workflow. This integration utilizes the execjob_begin, execjob_epilogue, execjob_end, and exechost_periodic hook events.
System/GPU Validation & Health Checks
The integration will call the NVIDIA DCGM health checks and analyze the results, which could be pass, warning, or failure. Ideally we would want everything to pass, but as we know, the system can have troubles. When the integration detects warnings and failures, the following events will be triggered:
1. Offline node; no longer eligible to accept new jobs
2. Record failure in daemon log
3. Set time stamped comment on node
4. Record failure in user’s ER file
The difference between a warning and a failure is that if there is a warning, the integration will allow the job to continue executing. Otherwise, if there is a failure, the integration will requeue the job and allow the scheduler to identify healthy nodes.
In addition to health checks, the integration can also perform diagnostics as supported by the NVIDIA DCGM including software deployment tests, stress tests, and hardware issues. When integration detects any diagnostic check failing, the following events will be triggered:
1. Offline node; no longer eligible to accept new jobs
2. Record failure in daemon log
3. Set time stamped comment on node
4. Record failure in user's ER file
Per-Job GPU Usage
When the system and its GPUs pass the initial tests, then the integration will begin tracking the job’s GPU usage so that it can be recorded in the PBS Professional accounting logs when the job terminates.
The Results
As they say, “The proof of the pudding is in the eating.” To verify that the integration was working, the site submitted hundreds of High-Performance LINPACK (HPL) with GPU jobs to PBS Professional to exercise the health checks and GPU accounting.
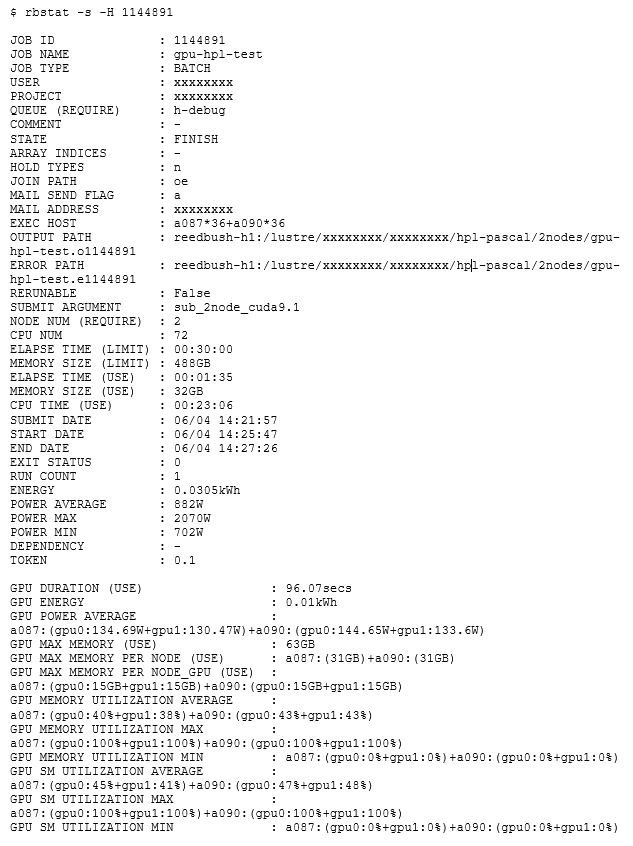
In this example, the NVIDIA GPUs are used very efficiently. In addition, HPE SGI Management Suite sets power resources for the jobs, which also increases the efficiency from the viewpoint of power usage, both for the whole node and the CPU usage rate. This example shows only 2 nodes with 2 GPUs each, but it has been confirmed that this monitoring and management works for a job scaling to 120 nodes (the whole system).
Below is a snippet of qstat -xf that illustrates one of the finished HPL jobs’ GPU usage

As you know, PBS Professional records a lot of information. Some may argue too much. Well, ITC developed a custom command, called rbstat, to extract specific job details and simplify the output for users and administrators:
Closing
The PBS Professional and NVIDIA DCGM integration has proven to be critical to ITC’s infrastructure to ensure that their users’ designs and scientific discoveries run to completion. In addition, the integration is providing administrators and users more insight into the utilization of the system and GPUs, which is knowledge that can be used for future procurements.
Although this example focused on an aspect of integrating with NVIDIA DCGM, the same capability is hardware- and OS-agnostic and can be used with any system. I hope this example has given you some ideas about what can be done to customize your site and fulfill your evolving requirements and demands from users to report on site-specific metrics. For more information, a copy of the hooks, or follow-up questions, please feel free to leave a comment below.
Want to learn more? Join Altair and NVIDIA for a FREE live webinar on June 25th! Register now to save your spot for "Boosting Your GPU Performance in a Highly Complex HPC Environment"
Acknowledgments
The authors would like to thank the Information Technology Center, the University of Tokyo, Hewlett Packard Enterprise, Altair, and NVIDIA Corporation, who supported the deployment of this integration.
Reference
Altair® PBS Professional® 13.1 Administrator’s Guide
Altair® PBS Professional® 13.0.500 Power Awareness Release Notes
GPU-Accelerated Computing Made Better with NVIDIA DCGM and PBS Professional® (https://www.altair.com/NewsDetail.aspx?news_id=11273)
NVIDIA Data Center GPU Manager (DGMC) Overview & Download (https://developer.nvidia.com/data-center-gpu-manager-dcgm)
NVIDIA Data Center GPU Manager Simplifies Cluster Administration, By Milind Kukanur, August 8, 2016 (https://devblogs.nvidia.com/nvidia-data-center-gpu-manager-cluster-administration/)